
Voice Agents: TL;DR of Week 1

Who is this TL;DR for?
If you're short on time but want to understand what goes into building production-grade voice AI agents, this post condenses the key insights from the first week of the Voice AI course by Daily.co.
Ideal for:
- Builders shipping voice-first agents
- Devs optimizing real-time latency and infra
- Anyone exploring telephony and WebRTC use cases in AI
What is a Voice Agent?
A voice agent is an AI-powered system that listens, thinks, and speaks back. Core pipeline:
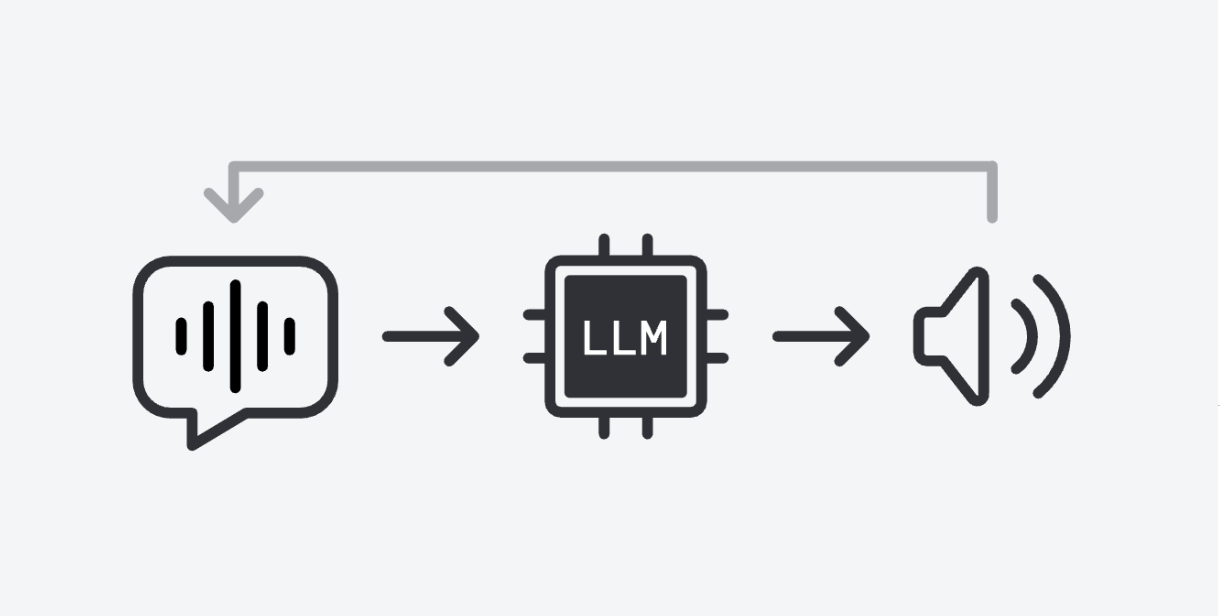
But this is just the surface. Real-time voice requires solving deep systems challenges:
- Low-latency networking
- Turn detection
- Interruption handling
- Context management
- Function calling and tool use
- Scripting and instruction following
- Memory and retrieval
- Integration with legacy systems
Voice AI Stack Today
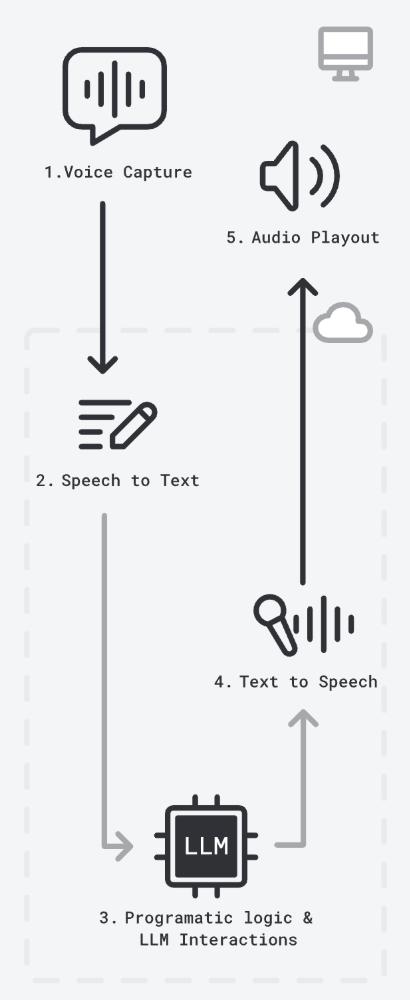
The typical voice AI loop looks like this:
- Convert voice to text (STT)
- Process with LLM (context + memory)
- Convert response to voice (TTS)
For each of these steps, you have to choose a model that not only fits the task, but also fits the latency budget. A few good model choices for each step are listed below:
- STT: Deepgram, Gladia, Whisper
- LLM: GPT-4o, Gemini 2.0 Flash
- TTS: Cartesia, Rime, ElevenLabs
Keep in mind that all of this must happen under 1 second to feel natural.
Network Layer
The network layer is the most critical part of the stack. It's the only way to get real-time audio between the client and server. Choose the correct protocol based on your use case. The following is a breakdown of which protocol is best for which use case:
- WebSockets: TCP based, Good for server-to-server, not optimal for server-to-client real-time audio
- WebRTC: UDP based, Gold standard for low-latency, bidirectional client-server audio/video and built-in media controls
- PSTN / SIP: For dial-in/out phone calls, legacy infra
Latency Breakdown (Worst Case ~993ms)

- STT and LLM are biggest bottlenecks (~650ms combined)
- Turn detection, sentence aggregation, and speaker output also matter
- Small gains across the stack = big user perception improvements
Note: This worst-case breakdown image is old now, but the principles are still relevant. Models have improved and latency has decreased. However, this should give you a good ballpark for the latency of a voice agent.
Hosting & Infrastructure
Traditional Web Apps vs Voice AI
| Traditional App | Real-time Voice AI |
|---|---|
| Short-lived requests | Persistent connection (minutes) |
| Request / response pattern | Streaming bidirectional data |
| Stateless | Stateful sessions |
| High volume, low duration | Lower volume, longer duration |
| More predictable resource usage | Variable resource consumption |
Resource Allocation
The following is a general rule of thumb for resource allocation for your voice agent. This should serve as a starting point that you can further optimize for your specific use case.
- ~0.5 vCPU & 1GB RAM per voice agent
- ~40kbps per agent via WebRTC
- Optimize for cold-starts: warm instances, scheduling, caching
Deployment Strategy
Keep in mind that time to first word matters a lot. People have a perception that phone callse are usually answered between 3-5 seconds. Your goal should be to optimize for this metric.
As for the deployment strategy, here are some general tips:
- Start simple: Start with a simple container solution and lightweight tooling (Docker, Fly.io, etc.). You can always scale your services on AWS, GCP, etc. later.
- Optimize: Warm pools, scheduling, drain timers
- Scale: Reactive (demand-based) or Predictive (historical patterns)
Run warm instances to ensure that resources are always available to handle requests. Pre-warm your instances when you expect a spike in traffic.
Understand the resource usage patterns and predictively scale your instances based on demand. Invest in ways to reduce cold-starts.
Infra Providers
- ML-native: Modal, Cerebrium, Baseten
- Hyperscalers: AWS, GCP
- Voice-native: Vapi, Pipecat, Layercode
Telephony: Connecting to Real Phones
PSTN (Public Switched Telephone Network)
- Connects to real phone numbers
- Use cases: call centers, general public
- Providers: Twilio, Telnyx, SignalWire
SIP (Session Initiation Protocol)
- Enterprise IP telephony
- Greater control over complex call flows
WebRTC
- For high-fidelity audio in browsers
- Track-level control, better quality
Advanced Call Features
- DTMF Handling: Capture user keypad inputs (e.g., 1 for sales)
- Cold Transfer: Redirect to another number instantly
- Warm Transfer: Bot speaks to agent before handing off
Open Source Tools
- Smart Turn Detection
- Open weights + code + training data
- Hosted on: https://fal.ai/models/fal-ai/smart-turn
- Docs: https://docs.pipecat.ai/server/utilities/smart-turn/
Resources
- https://voiceaiandvoiceagents.com/
- Pipecat Examples:
Key Takeaways
- Voice agents are real-time, multimodal, and hard.
- You’re not just doing LLMs, you’re solving infra + audio + network + UX.
- WebRTC and pre-warmed infra are critical.
- Telephony is a first-class citizen, not an afterthought.
- Everything breaks without tight latency control.