
RAG for Startups with Limited Budget and Time

Why this article?
RAG isn't simple. Building a good pipeline involves navigating countless variables, especially when you're dealing with unstructured data—media files, languages, formats, and more. The complexity alone is daunting.
But it becomes even more challenging when you're a startup or indie hacker juggling two major constraints:
- Limited budget
- Limited time
In this article, I’ll share my hands-on experience building a RAG pipeline under these constraints—the challenges I encountered, the experiments I ran, and how I solved the puzzle piece by piece. My goal: cut through the fluff and give you actionable insights, fast.
What is RAG?
RAG stands for Retrieval-Augmented Generation. It’s a technique that enhances LLM output by injecting relevant context retrieved from a vector database.
Here’s the basic flow:
- A user asks a question.
- The question is converted into a vector.
- The system searches for similar vectors in a database.
- The top matches are retrieved.
- These matches are fed into the LLM to generate an answer.
To build this, you'll need:
- Embedding model (e.g., OpenAI's text-embedding-3-small)
- Vector database (e.g., Milvus)
- LLM (e.g., GPT-4o)
- ETL pipeline (e.g., Unstructured)
Let’s break down the complexity of each part, starting with ETL.
ETL (Extract, Transform, Load)
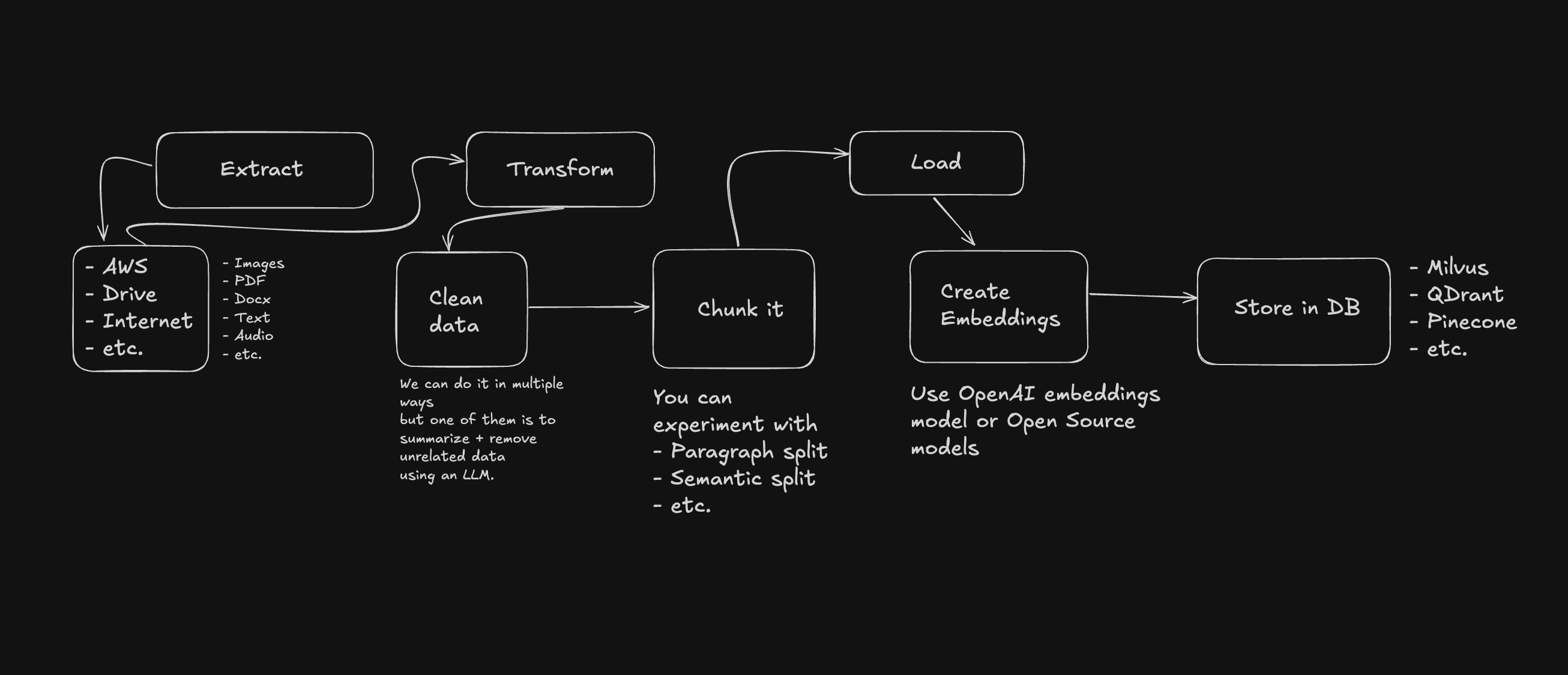
Data Types
You’ll deal with two major categories:
- Structured data (e.g., CSV, JSON, tables)
- Unstructured data (e.g., PDFs, images, videos, raw text)
If it’s structured—great! The format helps you understand and split the data easily.
Unstructured? Welcome to chaos. You’ll encounter varying formats and quality, with 80% being junk. Isolating the valuable 20% is tough but essential.
Let’s tackle each ETL step:
Extract
You'll need to pull data from different storage types:
- Local storage
- Cloud storage (Google Drive, Dropbox)
- Databases (MySQL, PostgreSQL)
- CDNs (Cloudflare R2)
- Web scraping
- APIs
And from various media formats:
- PDFs
- Images
- Videos
- Audio
- Text files
To simplify, you could either force users to upload to a common system or use a third-party service to unify data ingestion.
Transform
The goal: turn raw data into high-quality, semantically rich chunks.
With structured data, transformation is easy. But with unstructured data, you’ll need smart decisions:
- For PDFs: extract text + structure
- For images: detect text, diagrams, or tables
- For videos: transcribe with STT (Speech-to-Text) and then chunk
Once you extract the content, clean the noise:
- Use LLMs for summarization
- Apply NLP methods (e.g., TF-IDF, relevance scoring)
Then, split the text meaningfully:
- Token/sentence-length chunking
- Semantic chunking
- Chunk overlap for context retention
You can explore more advanced RAG techniques here.
Tools like LlamaParse (or open source LlamaIndex), Unstructured, Chonkie, and LangChain can help you with the entire ETL process for both structured and unstructured data.
Note: open-source tools save money but often require significant time and effort. They also severely lag behind the paid services to the point that some paid options that started as open-source think of their open-source counterparts as an afterthought now.
Load
This step involves storing vectors in a database. Options include:
A few key metrics to consider when choosing a vector database:
- Performance
- Cost
- Multi-tenancy
For example, storing vectors for multiple users requires a different structure. Vector isolation plays a really important role in better recall. You can watch this talk by Anton Troynikov (ChromaDB) on organizing data for multi-user queries to better understand how.
If you were to choose a DB like Pinecone, you might not be able to create unlimited pods and will have to rely on namespaces to isolate data and they are a virtual separation.
Retrieval
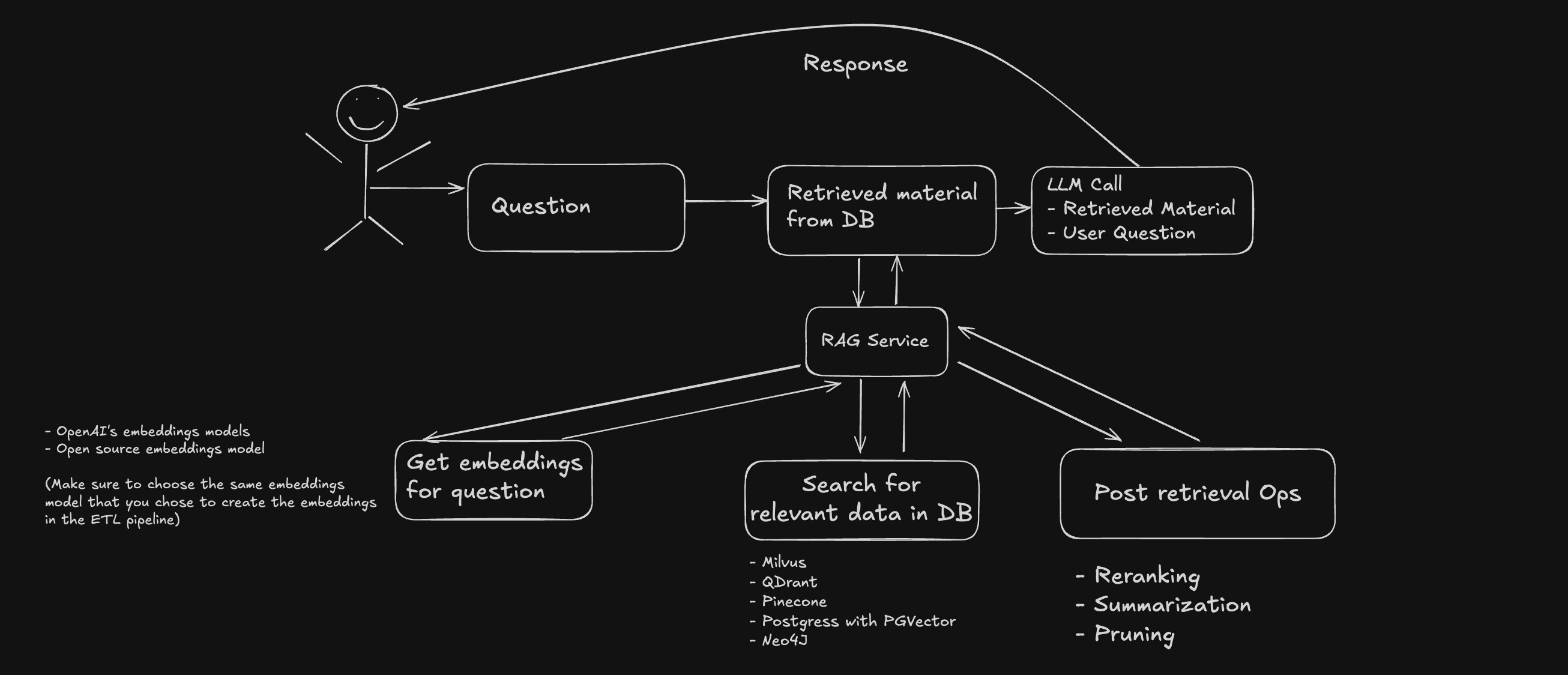
Once the ETL pipeline is complete, your database is ready for action.
Relevant Data Retrieval
- Convert the query into a vector.
- Retrieve top-matching chunks.
- Tune similarity functions.
- Explore hybrid search (metadata + embeddings).
- Consider BM42 for scoring.
After retrieval, re-rank with tools like Cohere Rerank. You might need to summarize data to stay within the LLM’s context window—adding more services, costs, and latency.
Augmentation + Generation
This part is relatively easy—plug the retrieved content into your LLM prompt, and you're done.
Key Considerations for Startups
When you're building with constraints, you need a smart strategy:
- Understand each component.
- Cut features that aren’t essential. While leaving enough room to grow in the future.
- Focus on scalability, maintainability, and cost.
ETL Service
Look for generous free tiers or startup credits. LlamaParse and Unstructured are great but they don't offer a generous free tier. Their open-source versions can be good starting points but they will be limited and you will end up manually building a pipeline that works for you.
Vector DB
This is the engine of your RAG system. I chose Milvus via Zilliz Cloud for its speed, open-source nature, and generous free tier. I considered self-hosting but ruled it out due to time constraints.
LLM
Start with OpenAI’s text-embedding-3-small—cheap and performant. Down the line, you can look into fine-tuning open-source models.
Final Thoughts
Here’s what I learned:
- Messy unstructured data slowed down ETL.
- Bad outputs forced me to tweak augmentation.
- Low recall led me to rework retrieval.
Each fix forced me back to square one. Eventually, I realized I needed a shortcut—a ready-made RAG pipeline I could later swap out.
My Requirements
- Cheap
- Fast with high recall
- Easy to integrate
- Supports unstructured data
- Multi-tenant ready
I chose Sid.ai. It passed my tests, worked out of the box, and only required minor pre-processing like converting video to text.
If you’re in a similar spot—limited budget, limited time—consider doing the same. You can modularize your pipeline and swap it with your own once you have found traction.
One Last Thing
This might sound like the most anti-climactic advice I’ve ever given—but honestly, just use a third-party RAG service. I know, it doesn’t feel very hacker-core or satisfying, but hear me out: it’s often the smartest move.
Think of it like auth—you wouldn’t build your own authentication system from scratch before product-market fit, right? The same logic applies here. Until you know you need an in-house RAG solution (and can afford the time to build and maintain it), let the experts handle the heavy lifting so you can focus on shipping your actual product.